
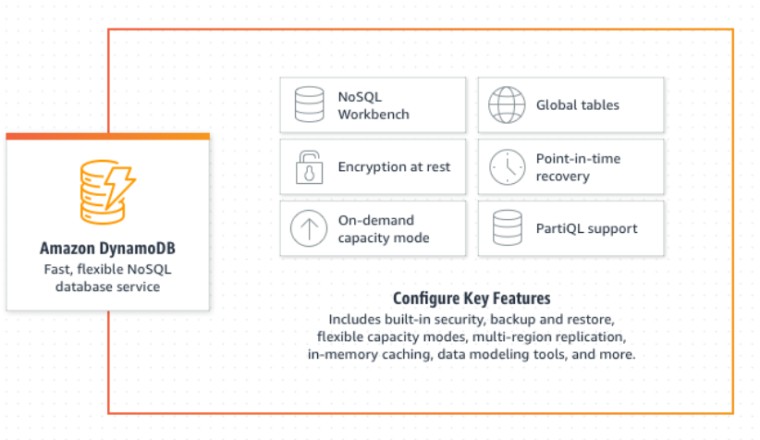

Amazon DynamoDB ฐานข้อมูลแบบ NoSQL ของ AWS มีอายุครบรอบ 10 ปีแล้วในปีนี้ (ออกเวอร์ชัน GA ในเดือนมกราคม 2012) ในโอกาสนี้ทำให้ AWS เล่าเบื้องหลังการสร้าง DynamoDB ขึ้นมา
เรื่องเริ่มจากเทศกาลคริสต์มาสปลายปี 2004 ที่มียอดสั่งซื้อเป็นจำนวนมาก ทำให้ระบบอีคอมเมิร์ซของ Amazon ที่ตอนนั้นใช้ฐานข้อมูลแบบ relational ถึงกับพัง เป็นสัญญาณบอกว่าฐานข้อมูลแบบ relational ถูกใช้จนถึงขีดจำกัดแล้ว
ทีมวิศวกรรมของ Amazon มีกระบวนการเรียกว่า Correction of Error (COE) มาพูดคุยทบทวนถึงปัญหาเทคนิคที่เกิดขึ้น เพื่อบันทึกไว้ไม่ให้เกิดซ้ำ ในการประชุมครั้งนั้นมีนักศึกษาฝึกงานอายุ 20 ปีชื่อ Swaminathan (Swami) Sivasubramanian ทักขึ้นมาว่าทำไมเรายังต้องใช้ฐานข้อมูลแบบ relational กัน เพราะตัวเนื้องานของ Amazon ไม่จำเป็นต้องใช้ความซับซ้อนระดับภาษา SQL และไม่จำเป็นต้องการันตี transaction ที่เกิดขึ้น
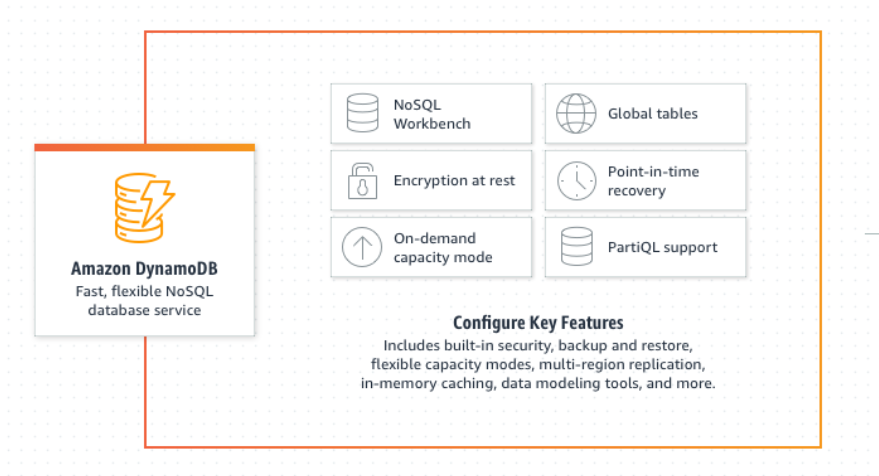
เหตุการณ์นั้นทำให้ทีมวิศวกรรมของ Amazon สร้างแนวคิดฐานข้อมูล Dynamo ขึ้นมา โดยมีโจทย์เรื่องการขยายตัว (scalability) และเสถียรภาพ (reliability) เพื่อตอบโจทย์ของธุรกิจอีคอมเมิร์ซ จนออกมาเป็นเปเปอร์ชื่อ Dynamo ในปี 2007 ที่มีแนวคิดของฐานข้อมูลแบบ key-value
เปเปอร์ Dynamo ถูกนำไปใช้งานโดยทีมภายในต่างๆ ของ Amazon ซึ่งพบว่าฐานข้อมูลมีประสิทธิภาพ เสถียรภาพ และรองรับการขยายตัวตามเป้าหมาย แต่ยังเจอปัญหาการติดตั้ง คอนฟิก และใช้งานตัวซอฟต์แวร์ภายในเครื่องของ Amazon เอง
ในช่วงเวลาเดียวกัน AWS ในฐานะบริการคลาวด์เพิ่งเริ่มต้นขึ้นเช่นกัน (เริ่มบริการครั้งแรกในปี 2002) โดย AWS ผลักดันฐานข้อมูล NoSQL อีกตัวคือ Amazon SimpleDB แต่ก็พบปัญหาในการสเกลเมื่อข้อมูลมีขนาดเกิน 10GB จะเริ่มมีระยะเวลา latency ไม่สม่ำเสมอ (ปัญหาเกิดจากขนาดของฐานข้อมูลและตัวดัชนี)
AWS จึงนำแนวคิดเรื่องการสเกลและ latency ที่สม่ำเสมอของ Dynamo มารวมร่างกับความเรียบง่ายในการดูแลของ SimpleDB จนออกมาเป็น DynamoDB ในท้ายที่สุด
ส่วน Swami นักศึกษาฝึกงานคนนั้น ร่วมเขียนเปเปอร์ Dynamo และปัจจุบันเป็น VP of the database, analytics, and ML ที่ AWS
ที่มา - AWS Blog



















